6 Adattábla műveletek
Az adattábla egészén a Data → Active data set menüvel (6.1. ábra) különböző műveleteket végezhetünk:
- View data Az aktuális adattábla vagy egy részének megtekintése. Hasonlóan működik, mint a Rész adattábla leválogatása (6.1. fejezet), azzal a különbséggel, hogy nem jön létre új táblázat.
- Select active data set Aktív adattábla kiválasztása
- Refresh active data set Aktív adattábla frissítése, ha valamilyen változtatást hajtottunk végre rajta
- Help on active data set (if available) Az aktív adattáblához tartozó súgó betöltése, ha van (általában R csomagokból betöltött adatállományok esetén van erre lehetőség)
- Variables in active data set Az aktív adattábla változói
- Set case names… Beállíthatjuk, hogy az aktív adattábla mely oszlopa tartalmazza a megfigyelések (esetek) megnevezését.
A további lehetőségeket részletezzük.
- Subset active data set… Rész adattábla leválogatása (6.1. fejezet).
- Sort active data set… Rendezés (6.2. fejezet).
- Aggregate variables in active data set … Adattábla aggregálása (6.3. fejezet).
- Remove row(s) from active data set… Sorok eltávolítása (6.4. fejezet).
- Stack variablesn in active data set… Több változó összefűzése egy változóba (6.5. fejezet).
- Remove cases with missing data… Hiányzó értékeket tartalmazó esetek eltávolítása (6.6. fejezet).
- Save active data set… Aktív adattábla mentése (6.7. fejezet).
- Export actve data set… Exportálás (6.8. fejezet).
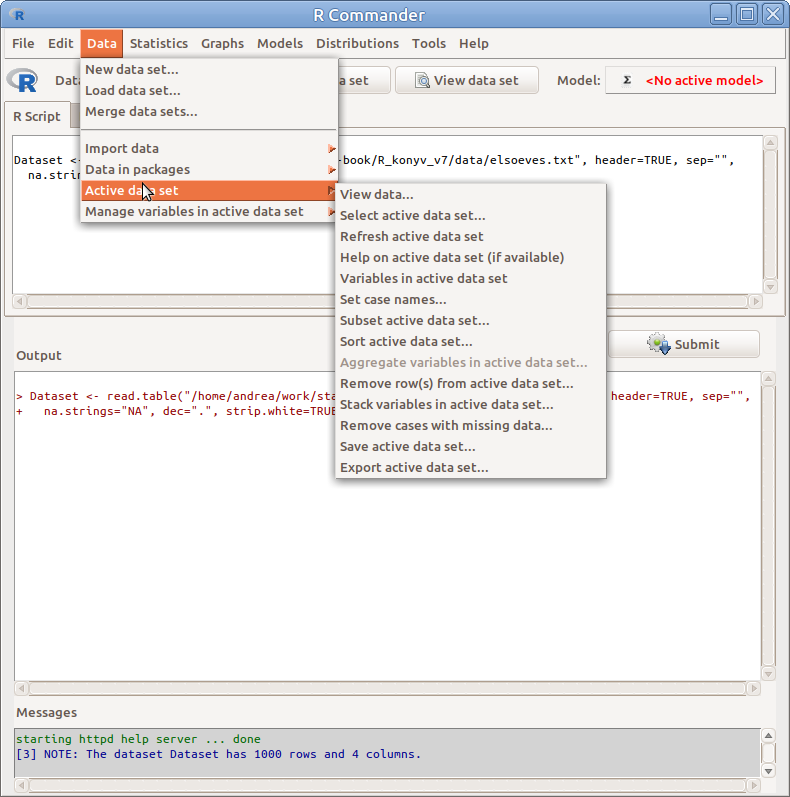
6.1: ábra Adattábla műveletek: Data → Active data set
6.1 Rész adattábla leválogatása
Az aktív adattáblából leválogathatunk eseteket, illetve változókat a Data → Active data set → Subset active data set… menüpont segítségével (6.2. ábra). Alapértelmezésben az összes változót leválogatjuk (Include all variables), vagy kiválaszthatjuk közülük a szükségeseket (Variables (select one or more)).
Az esetek leválogatásához egy logikai kifejezést kell megadnunk. Ez általában úgy néz ki, hogy megadjuk, hogy egy adott változó milyen értékeket vehet fel, illetve több ilyet összekapcsolhatunk ‘ÉS’-sel illetve ‘VAGY’-gyal. A felhasználható operátorokat a 2. táblázat tartalmazza. Faktor illetve szöveges változó esetén az értékeket idézőjelbe, vagy aposztrófok közé kell tenni. Lássunk néhány példát a pop adattáblázattal (ld. 4 fejezet)!
biol == 5 |
biológiából 5-öst kapottak |
magas >= 170 |
legalább 170 cm magasak |
matek.kat == 'rossz' |
rossz matekosok |
biol == 5 & matek == 5 |
matekból is és biológiából is 5-öst kapottak |
biol == 1 \| matek == 1 |
matekból és/vagy biológiából bukottak |
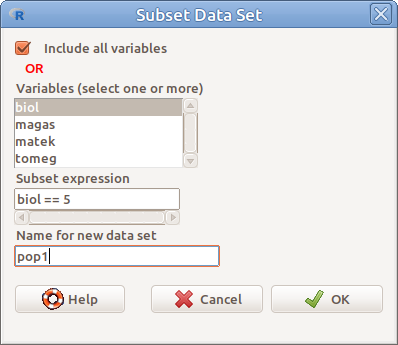
6.2: ábra Résztábla leválogatása: Data → Active data set → Subset active data set…
- táblázat: Résztábla megválogatáshoz használható operátorok
| Operátor | Leírás |
|---|---|
| < | kisebb |
| <= | kisebb vagy egyenlő |
| > | nagyobb |
| >= | nagyobb vagy egyenlő |
| == | egzaktul egyenlő |
| != | nem egyenlő |
| !x | Nem x |
| x | y | x vagy y |
| x & y | x és y |
| isTRUE(x) | X igaz-e |
Végül meg kell adni a rész adattábla nevét (Name for new data set).
A Script ablakban például a következő kód jelenik meg:
pop1 <- subset(pop, subset= biol == 5)(R bevezető 0.8. fejezet)
6.2 Adattábla rendezése
Az aktív adattáblát rendezhetjük egy vagy több változó értékei szerint a Data → Active data set → Sort active data set… menüpont segítségével (6.3. ábra). Ki kell választanunk a változókat, amik alapján a rendezést el akarjuk végezni (esetünkben biol és matek), be kell állítani szükség esetén, hogy csökkenő sorrendeben (Decreasing) akarjuk-e a rendezést, illetve egy új nevet kell adni az adattáblázatnak, ha szükséges (Name for new data set), majd az OK gombra kattintás után, be kell állítani, hogy a kiválasztott változókat milyen sorrendben vegye figyelembe a rendezéskor (6.4. ábra).
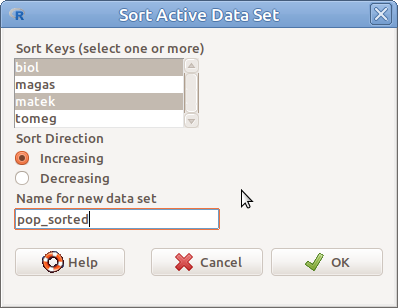
6.3: ábra Adattábla rendezése: Data → Active data set → Sort active data set…
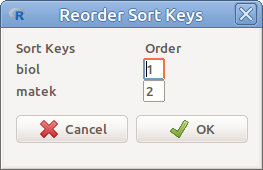
6.4: ábra Rendező változók sorrendjének beállítása
A Script ablakban a következő kód jelenik meg:
pop_sorted <- with(Dataset, Dataset[order(biol, matek, decreasing=FALSE), ])(R bevezető 0.7.3. fejezet, Rendezés)
6.3 Aggregált táblázat készítése
Aggregáláskor valamely kategóriás változó vagy változók kategóriái szerint csoportosított adatok összesítő statisztikáit számoljuk ki. Példaként a lepke táblázat BABTOMEG illetve TOMEG0 változóinak számítsuk ki az átlagait a HOM és TAP csoportokban (6.5. ábra).
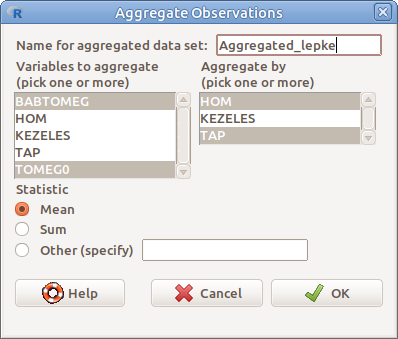
6.5: ábra Aggregált táblázat készítése: Data → Active data set → Aggregate variables in active data set …
- Name of aggregated data set Az aggregált táblázat neve
- Variables to aggregate Aggregálandó változók
- Aggregate by Csoportosító változók
- Statistic Összesítő statisztika
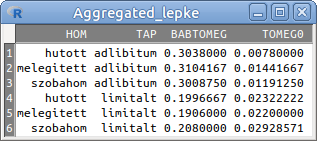
6.6: ábra Az aggregált lepke táblázat
Az aggregálás eredménye az Aggregated_lepke táblázat lett, amelyet a View data set gomb megnyomásával megnézhetünk (6.6. ábra).
A Script ablakban a következő kód jelenik meg:
Aggregated_lepke <- aggregate(AggregatedData[,c("BABTOMEG","TOMEG0"), drop=FALSE], by=list(HOM=AggregatedData$HOM, TAP=AggregatedData$TAP), FUN=mean)6.4 Sorok eltávolítása
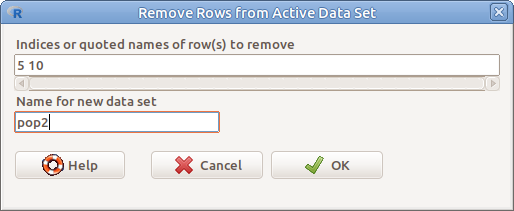
6.7: ábra Sorok eltávolítása: Data → Active data set → Remove row(s) form active data set…
Adott sorszámú, vagy megnevezésű sorok eltávolítása az adattáblázatból (6.7. ábra).
pop2 <- pop[-c(5,10),]6.5 Több változó összefűzése egy változóba (Stack variables…)
Ezzel a lehetőséggel fűzhetünk össze több oszlopban elrendezett adatokat egy oszlopba. Például, ha a lepke táblázat TOMEG0 és BABTOMEG változóiba elrendezett tömegértékeket egy tomeg változóba akarjuk rendezni úgy, hogy egy meres nevű új változóban tüntetjük fel, hogy melyik mérésről van szó, akkor 6.8. ábrán látható módon kell kitölteni a párbeszéd ablakot. Eredményül a 6.9. ábrán látható táblázatot kapjuk.
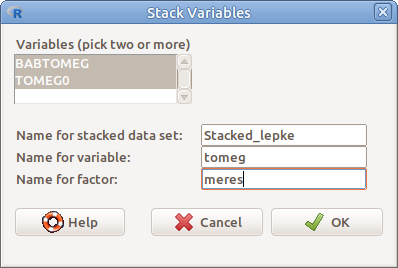
6.8: ábra Több változó összefűzése: Data → Active data set → Statck variables in active data set…
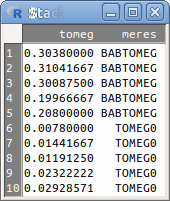
6.9: ábra Összefűzött BABTOMEG és TOMEG0 változók a lepke táblázatból
6.6 Hiányzó értékeket tartalmazó esetek eltávolítása
Eltávolíthatjuk a hiányzó értékeket tartalmazó sorokat a teljes táblázatból, vagy kiválasztott változókból (az új táblázatban csak a kiválasztott változók fognak szerepelni). A 6.10. ábra szerinti beállítások esetén a lepke táblázat BABTOMEG és HOM változóiból eltávolítjuk a hiányzó értékeket tartalmazó sorokat, és ezekből a változókból elkészítjük a lepke1 táblázatot.
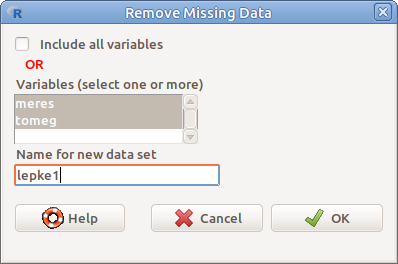
6.10: ábra Hiányzó adatokat tartalmazó esetek eltávolítása: Data → Active data set → Remove cases with missing data…
lepke1 <- na.omit(lepke1[,c("BABTOMEG","HOM")])(TK. 2.4.4. fejezet)
6.7 Az aktív adattábla mentése
A Data → Active data set → Save active data set… menüponttal az aktív adattáblát menthetjük el az R saját adatformátumában (.RData).
(TK. 12.5. fejezet)
6.8 Az aktív adattábla exportálása szöveges táblázat formátumba
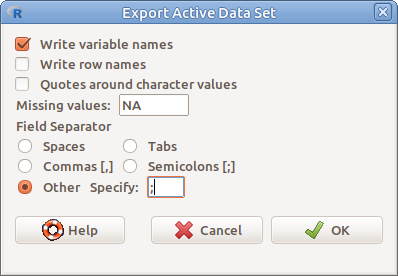
6.11: Adattábla exportálása: Data → Active data set → Export active data set…
Az aktív adattáblát szöveges állományként menthetjük (6.11. ábra). Az exportáláshoz meg kell adnunk a következőket:
- Write variable names Változónevek kiírása
- Write row names Sornevek kiírása
- Quotes around character values Szöveges mezők idézőjelben
- Missing values Hiányzó adat jelölése
- Field separator Mezőhatároló karakter:
- Spaces Szóközök
- Tabs Tabulátorok
- Commas [,] Vesszők
- Semicolons [;] Pontos vesszők
- Other Specify Egyéb, megadandó
Magyar beállítású Excel táblázatkezelőbe importáláshoz célszerű a 6.11. ábrán bemutatott beállításokat alkalmazni, és .csv kiterjesztést adni az exportált táblázatnak.
write.table(lepke1, "data/lepke1.csv",
sep=";", col.names=TRUE, row.names=FALSE, quote=FALSE, na="NA")(TK. 12.5. fejezet, R bevezető 0.11. fejezet)