1 Bevezetés
1.1 Miért tanuljunk statisztikát?
Erre a kérdésre több lehetséges válaszunk is van. Lássunk néhányat:
Azért, hogy el tudjuk dönteni, elhiggyünk-e valamit, amit olvasunk, vagy hogy észrevegyük, hol van benne a hiba, vagyis hogy ne dőljünk be olyan könnyen a statisztikai bűvészkedéseknek, műtermékeknek és tévedéseknek. Lássunk néhány példát!
,,Egy 2002-es tanulmány szerint azok, akik naponta nyolc óránál többet alszanak, az átlagosnál jóval nagyobb valószínűséggel halnak meg.’’
,,A Nemzeti Autópálya Rt. adatai szerint a matricák 85 százalékát személygépkocsikra, 15 százalékát teherautókra veszik, ami azt jelzi, hogy a fizető utak tarifáit a személygépkocsik tulajdonosai elfogadták. Ez a százalékos eloszlás egyébként lényegében megfelel a gépjárműállomány összetételének.’’
,,Hihetetlen mértékben emelkedett részvényeink ára az utóbbi időben (1.1. ábra).’’
,,Tavaly drámaian csökkentek a lakosság megtakarításai az előző évhez képest (1.2. ábra).’’
,,Csalás az átlagjövedelem számításában? Kiderült, hogy az emberek többsége kevesebbet keres, mint az átlagjövedelem KSH által közölt értéke!’’
,,Alvászavart okozhat a papírzsebkendő használata! 1500 fős reprezentatív mintán végzett vizsgálatunkban a 30 és 40 év közötti vidéki diplomás férfiak körében erősen szignifikáns (\(p=0.009\)) összefüggést találtunk a papírzsebkendő használata és az alvászavarok előfordulása között.’’
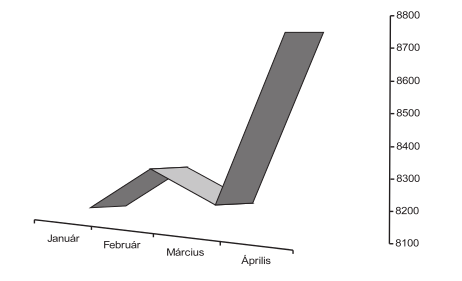
1.1: ábra. Részvényárak

1.2: ábra. Lakossági megtakarítások
Reméljük, hogy a Kedves Olvasó nem sajnál némi fejtörést, hogy megtalálja a hibákat, illetve kifogásolható pontokat a fenti állításokban és következtetésekben (a megoldásokat lásd a következő részben).
Azért, hogy jobban meg tudjuk ítélni, hogy szerencsénk volt-e, vagy pechünk – vagy éppen egyik sem: ami történt, az általában így szokott történni, ez a dolgok normális menete.
*Az autóbusznak, amellyel nap mint nap járok, a tábla szerinti követési ideje 15 perc. Mivel nincs pontos menetrendje, úgy számoltam, hogy átlagosan hét és fél percet kell várnom rá, de egy idő után az volt az érzésem, hogy a helyzet ennél sokkal rosszabb. Nem voltam rest, lemértem 50 várakozási időt, és ezekből az jött ki, hogy átlagosan 11 percet kell várnom a buszra. Ilyen peches lennék? Vagy a tábla nem mond igazat? Vagy ez csupán véletlen? (a megoldást lásd a következő részben)
Azért, hogy jobban meg tudjuk ítélni, mi mennyit ér, miért mennyit érdemes kockáztatni. (Érdemes megjegyezni, hogy a valószínűségszámítás kialakulásának idején – a tizenhetedik században – ezt az új tudományágat a szerencsejátékok rejtélyes világa inspirálta, és eredményeinek első alkalmazásai is a szerencsejátékok területén voltak.)
*Sorsjegyből 10000 db-ot nyomnak, közülük 1 fizet 1 millió forintot, 50 tízezret, 2449 pedig ezret (így ráírhatják, hogy ,,minden negyedik nyer legalább 1000, de akár 1 millió forintot’‘). A sorsjegyet 490 forintért árulják. Megéri-e játszani? Szerencsének tekintené-e, ha egy ilyen sorsjeggyel nyert? Pechnek tekintené-e, ha nem nyert? És ha vett tízet, és egyik sem nyert? Hogyan változnának a fenti kérdésekre adott válaszok, ha a 7500 ,,nem nyert’’ közül 1000-re azt írnák, hogy ,,újrahúzhat’’? (a megoldást lásd a következő részben)
Azért, hogy pontosan értsük a szakirodalmat.
,,A kísérlet során az állatok átlagos tömeggyarapodása a kezelt csoportban \(44.6 \pm 8.7\) kg (\(n=44\)), a kontrollban pedig \(40.7 \pm 14.7\) kg (\(n=48\)) volt. A közel 10%-os különbség az átlagok között jelentős, de statisztikailag nem szignifikáns (kétmintás Welch-féle \(t\)-próbával \(p = 0.1279\)). Ugyanakkor a szórások között a különbség szignifikáns (\(F\)-próbával \(p = 0.0007\)).’’
,,A vizsgálat szerint cukorbetegség esetén a stroke relatív kockázata a nem cukorbetegekhez képest 2.56 (95%-os konfidencia-intervallum: (1.37, 5.26), \(p = 0.009\)).’’
Azért, hogy saját vizsgálataink tervezését, illetve kiértékelését ügyesebben el tudjuk végezni.
Mekkora mintával dolgozzak? Elhagyhatok-e egy gyanús, hibásnak látszó adatot? Regresszió- vagy korrelációszámítást végezzek? A sok azonos célú – csak részleteiben különböző – varianciaelemzés modell közül melyiket használjam? Érdekes, váratlan eredményt kaptam: vajon most felfedeztem valamit, vagy csak a véletlen játéka, amit látok? Mennyire megbízható, mennyire pontos az eredmény, amit kaptam?
Azért, hogy eredményeinket érthetőbben és hatásosabban, a lényeget kiemelve tudjuk közölni.
Az ember gyakran bizonytalan: elég, ha megadom az átlagokat és a szórásokat? Minden átlaghoz külön adjam meg a szórást vagy csak egy közöset? Vagy az átlag helyett jobb lenne a medián? Esetleg kellene az előadásba néhány táblázat vagy ábra is? Ha ábra, akkor kördiagram vagy oszlopdiagram?
Sokan megszokásból, mások pedig ellesett minták alapján döntenek: ,,láttam egy hasonló témájú cikket, abban mediánt számoltak, és egy ilyen és ilyen ábra volt…’’
Reméljük, hogy mindezekben a kérdésekben segít eligazodni ez a tananyag.
1.2 Megjegyzések a példákhoz
A tudomány jelen állása szerint mindenki biztosan – tehát 1 valószínűséggel – meghal, azaz ennyi az elhalálozás átlagos valószínűsége is. És ezt már semmivel sem lehet növelni. Lehet, hogy a sok alvásnak van valamilyen kockázata, de az nem egyszerűen a halálozás valószínűségével kapcsolatos, hanem valamely betegségben való vagy az átlagosnál korábbi elhalálozáséval, esetleg az adott életkorban, adott egészségi állapot, életmód stb. melletti halálozási valószínűséggel. A cikkíró bizonyára minél rövidebben, a lényegtelen technikai részletek elhagyásával szerette volna összefoglalni a kutatás eredményeit, de sajnos épp az egyik legfontosabb részletet hagyta ki. (Az már más kérdés, hogy – még ha találtak is ilyen összefüggést – vajon ebből következik-e, hogy a magasabb kockázatnak valóban a sok alvás az oka. Oksági kapcsolat bizonyításához a statisztikai összefüggés kimutatása nem elegendő. Ezzel kapcsolatban lásd a ??. fejezetet is.)
Ha az eladott matricák 85–15%-os megoszlása megfelel a gépjárműállomány összetételének, akkor a személygépkocsik és tehergépkocsik tulajdonosai pont ugyanannyira fogadták el a tarifákat. De hogy valójában mennyire, arról ez a százalékos megoszlás semmit sem mond, hiszen a következtetést levonhatták akár az első 100 vagy 200 matrica eladása után is. Ebből a szempontból az lenne informatív, hogy a személy-, illetve tehergépkocsik hány százalékára vásároltak matricát (vagy még inkább az, hogy az autópályát potenciálisan igénybe vevő gépkocsik hány százalékára).
A perspektivikus ábrázolás, valamint az \(y\) tengely ,,ügyes’’ skálázása segít félrevezetni az olvasókat. A feltehetően megtévesztő szándékú előadó arra épít, hogy az ábra csak néhány másodpercig lesz látható, és ennyi idő a hallgatóságnak nem lesz elegendő a trükk leleplezésére. Az 1.3. ábra ugyanazokat az adatokat ábrázolja perspektíva nélkül, de megtartva az \(y\) tengely félrevezető skálázását. Az 1.4. ábrán látható a diagram úgy, hogy az \(y\) tengely 0-ról indul.
A piktogram kombinálva a térbeli ábrázolással azt eredményezi, hogy az olvasó a pénzeszsákokat nem magasságuk, hanem vélt térfogatuk szerint hasonlítja össze. Így a valójában 16%-os csökkenés több, mint 40%-os csökkenésként érzékelhető. Ugyanez a csökkenés egy egyszerű oszlopdiagramon sokkal kevésbé látszik drámainak (1.5. ábra).
Semmi különös nincs abban, hogy a népességnek több mint a fele helyezkedik el az átlag alatt. Soha nem állította senki az átlagról, hogy rendelkezne azzal a tulajdonsággal, hogy ugyanannyian vannak alatta, mint felette. Van ilyen statisztikai mutató is, de az nem az átlag, hanem a medián (további részletek a ?? fejezetben). Az átlag nem feltétlenül a tipikus, a hétköznapi, a leggyakoribb érték. Jól példázza ezt a következő meghökkentő állítás is: ,,Az emberek túlnyomó többségének az átlagosnál több lába van.’’ Valóban, különböző betegségek vagy balesetek miatt az emberek egy csekély hányada sajnálatos módon elveszíti egyik vagy mindkét lábát, aminek következtében az átlag egy kicsivel kettő alá csökken. Ugyanakkor az emberek túlnyomó többségének két lába van.
A megfogalmazásból látszik, hogy a vizsgált 1500 fős mintát életkor, nem, iskolai végzettség és lakóhely szerint csoportokra bontották. Feltehetően nem szerint kettő, kor szerint – a 10 éves osztályszélességből következtetve – legalább öt, iskolai végzettség szerint legalább három, lakóhely szerint legalább két csoportot képeztek. Ez összesen \(2 \cdot 5 \cdot 3 \cdot 2 = 60\) csoportot jelent. Ha ilyen sok csoport mindegyikében elvégezzük ugyanazt a statisztikai tesztet, akkor számítanunk kell arra, hogy néhányban – pusztán a véletlen folytán is – erős összefüggés mutatkozik. Ráadásul a szöveg azt sejteti, hogy a vizsgálat nem csupán a papírzsebkendőre és az alvászavarokra terjedt ki, hanem számos további adatra, tehát az elvégzett statisztikai tesztek száma akár több százra is rúghatott, vagyis nagyon valószínű, hogy a közölt eredmény semmit sem bizonyít (vö. a többszörös összehasonlításról írottakkal, ??. fejezet).
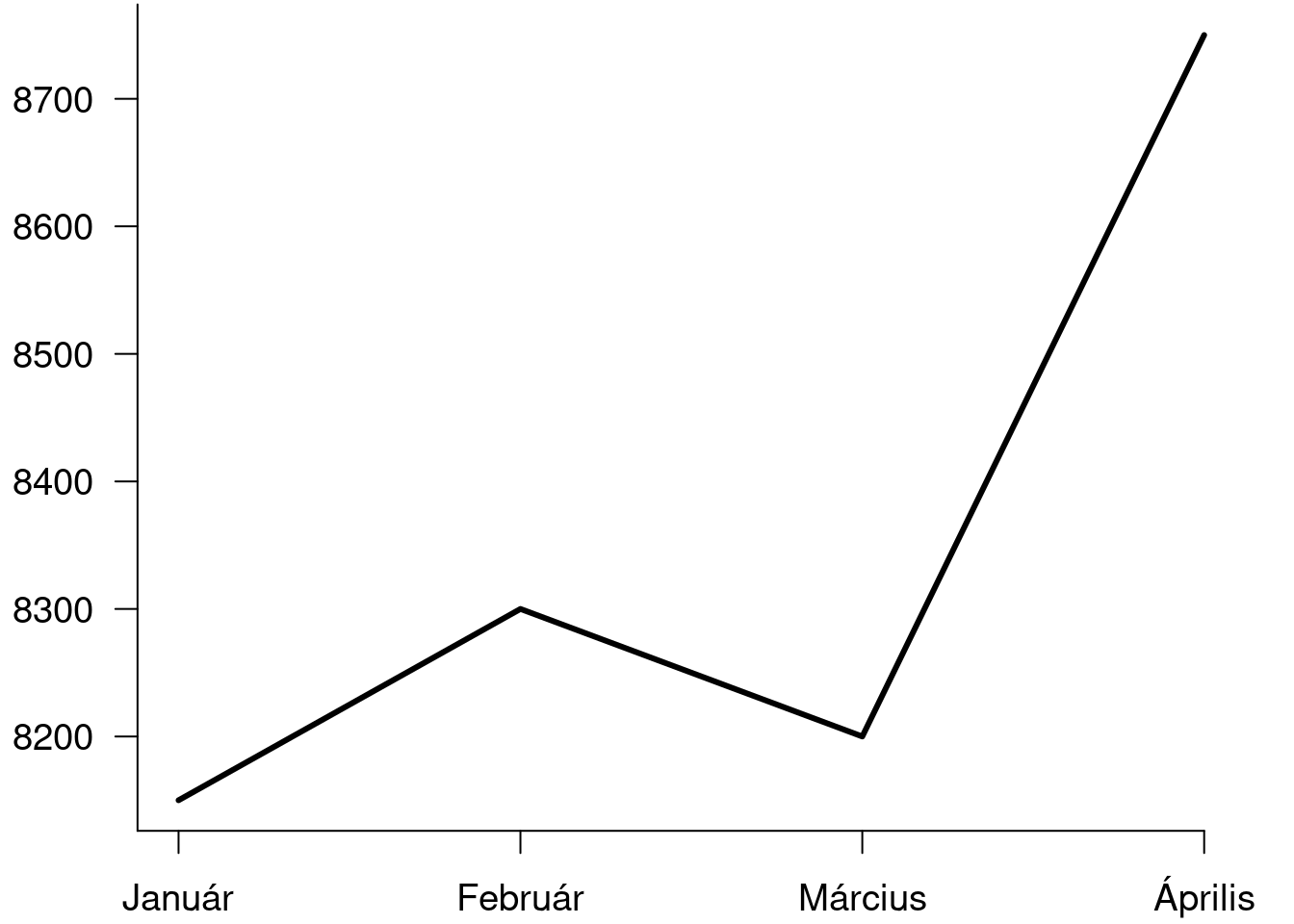
1.3: ábra. A részvényárak változásának grafikonja, ha az y tengely skálázása nem nulláról indul
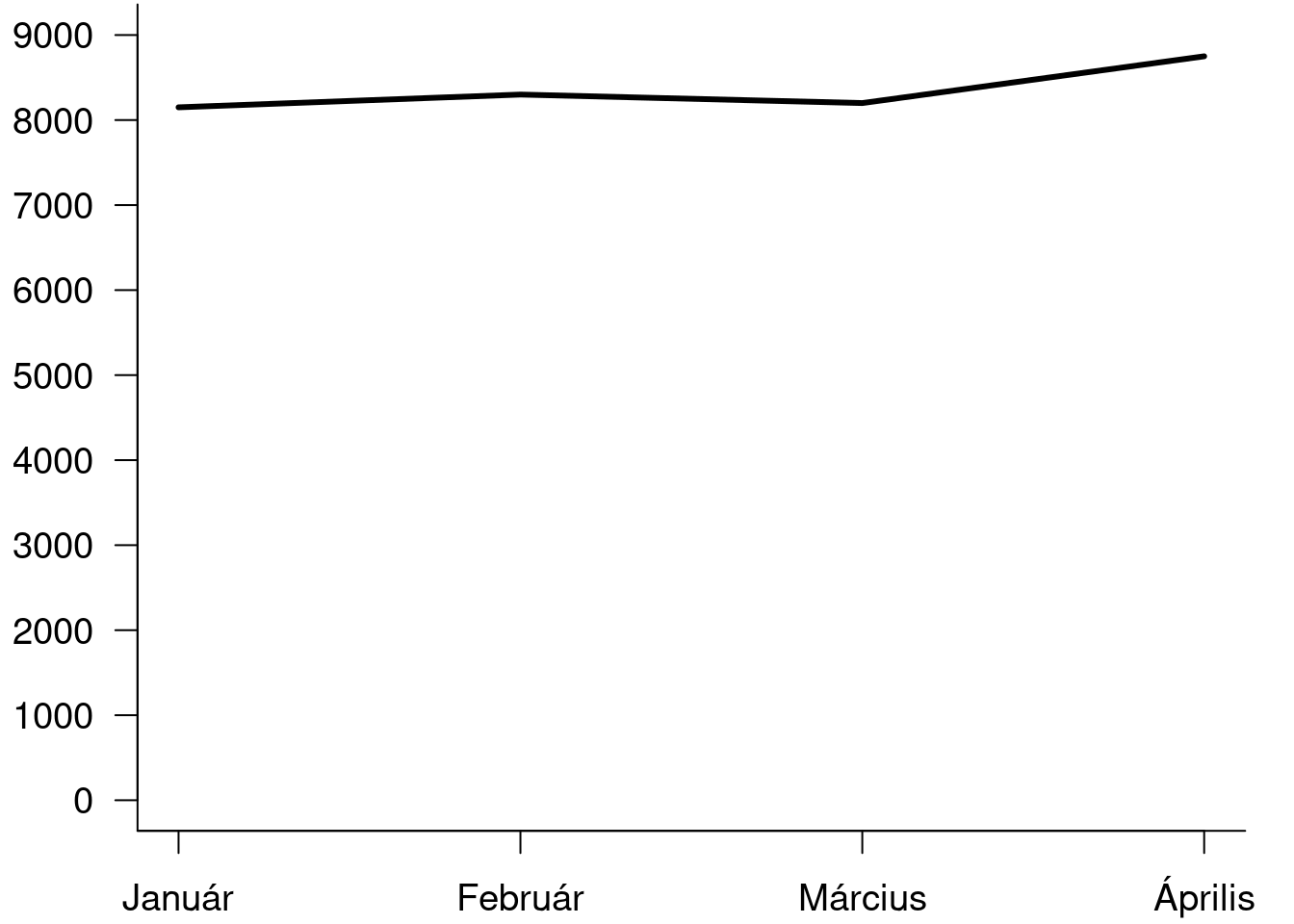
1.4: ábra. A részvényárak változásának grafikonja, ha az y tengely skálázása nulláról indul
1.5: ábra. Az oszlopok magasságának aránya ugyanakkora, mint az 1.2. ábrán lévő pénzeszsákok magasságának aránya, a piktogramon a különbség mégis nagyobbnak látszik
Lehet, hogy peches vagyok, az is lehet, hogy a tábla nem mond igazat, de abból a megfigyelésből, hogy az átlagos várakozási idő 11 perc, egyik sem következik. Az átlagos várakozási idő csak akkor lenne egyenlő a követési idő felével, ha a buszok teljesen szabályosan – mindig pontosan 15 percenként – követnék egymást, ez pedig a végállomástól távolabb eső megállókban (legalábbis a budapesti buszokra) már nem igaz. Ha a buszok nem pontosan 15 percenként jönnek, akkor az átlagos várakozási idő mindig hosszabb, mint az átlagos követési idő fele. Hogy mennyivel, az attól függ, mennyire szabálytalan időközökből jön ki az átlagos követési idő: annál nagyobb a különbség, minél nagyobbak az eltérések a szabályostól. Ezt számításokkal is lehetne bizonyítani, de nem akarjuk ezzel terhelni az olvasót. Mindenesetre az számolás nélkül is világos, hogy szabálytalan követési idő esetén valószínűbb, hogy az ember valamelyik hosszabb intervallumban érkezik a megállóba, mint az, hogy valamelyik rövidebben. Ez pedig megnöveli az átlagos várakozási időt, amely tehát szinte törvényszerűen nagyobb, mint az átlagos követési idő fele. Szemléltetésül képzeljük el például azt a végletes esetet, hogy így jönnek a buszok: harminc percig semmi, aztán két busz rögtön egymás után, megint harminc percig semmi, megint két busz egymás után stb. (Néha sajnos tényleg így jönnek …) Ekkor éppen megduplázódik az átlagos várakozási idő a szabályos követéshez képest.
A 10000 sorsjegy után kifizetendő összes nyereség \(1 \cdot 1 000 000 +50 \cdot 10 000 + 2 449 \cdot 1 000 = 3 949 000\) Ft, tehát az egy sorsjegyre jutó átlagos nyereség \(3 949 000 / 10 000 = 394.9\) Ft, ami 95.1 forinttal kevesebb, mint a sorsjegy ára. Tehát nem éri meg, csak az játsszon, aki bízik a szerencséjében! (Na jó, ezt gondolhattuk volna, hiszen a sorsjegy kibocsátójának is meg kell élnie valamiből…) Mivel a nyerés valószínűsége csak 25%, aki nyer, szerencsésnek mondhatja magát. Aki nem nyer, az viszont nem peches, csak éppen bejött a papírforma. Annak a valószínűsége, hogy tíz sorsjegyből egy sem nyer, \(\left(\frac{3}{4}\right)^{10} = 0.0056 = 5.6\%\), tehát aki így jár, az már jogosan bosszankodik. Ha 1000 sorsjegyre a ,,nem nyert’’ helyett ,,újra húzhat’’ kerül, akkor a 10000 sorsjegyből a vásárlók csak 9000 sorsjegyért fizetnek, 1000-hez az újra húzás révén ingyen jutnak hozzá. Így a sorsjegyek átlagos ára most 490 Ft helyett csak \(9000 \cdot 490 / 10000 = 441\) Ft, ami még mindig több, mint az átlagos nyereség. A nyerés valószínűsége most körülbelül 27.8%, tehát aki nyer, az most is szerencsés, aki nem, az pedig azt kapta, amire józanul számíthatott. Tíz sorsjeggyel nem nyerni viszont most még nagyobb pech, mint az előbb (valószínűsége kb. 3.9%).
A kezdők ebből bizonyára egy kukkot sem értenek, de aki a rég elfelejtett statisztikai ismereteit szeretné könyvünk segítségével feleleveníteni, annak talán rémlik, hogy ilyen közlésekben a \(\pm\) jel előtt a tömeggyarapodás átlaga, utána pedig a szórása szokott állni, az \(n\) pedig annak a mintának az elemszámát jelöli, amelyen a következtetések alapulnak. A ,,szignifikáns’’ és a ,,\(p\)-érték’’ fogalmak pontos jelentésére már bizonyára kevesebben emlékeznek. A statisztikai hipotézisvizsgálatok részletes ismertetését lásd 7. fejezetben, egyelőre csak annyit, hogy a ,,statisztikailag szignifikáns’’ nagyjából azt jelenti, hogy ,,több, mint véletlen’‘, azaz ,,nem nagyon hihető, hogy a véletlen játéka volna’’, a \(p\)-érték pedig számszerűen is megadja, mennyire valószínű, hogy a kapott eredmény a véletlen játékának tulajdonítható (tehát kis \(p\)-érték: szignifikáns, nem hisszük, hogy véletlen, nagy \(p\)-érték: nem szignifikáns, könnyen lehet, hogy véletlen). Az átlagok közötti különbségre kapott \(p\)-érték 0.1279, azaz ekkora különbséget az átlagok között közel 13% valószínűséggel a véletlen játéka (a biológiai változatosság, a mérési hibák stb.) is produkálhat. A szórások között tapasztalt mértékű eltérés ezzel szemben 1/1000-nél is kisebb valószínűséggel írható a véletlen számlájára, tehát bízhatunk benne, hogy ez valódi különbséget jelez. Jó szokás, ha mindig megadjuk az alkalmazott statisztikai teszt nevét is, hogy az olvasó tudja, melyik módszerrel kaptuk a közölt eredményt.
Az, hogy a relatív kockázat egy csoportban egy másik csoporthoz viszonyítva 2.56, azt jelenti, hogy a szóban forgó csoportban a betegség valószínűsége 2.56-szor akkora, mint a másik csoportban. Mivel a 2.56 értéket egy mintából kapták, ez nem feltétlenül egyezik meg a teljes populációban érvényes relatív kockázattal. A 95%-os konfidencia-intervallum egy olyan értéktartományt jelöl, amely 95% megbízhatósággal – azaz 5% tévedési valószínűséggel – tartalmazza a populációbeli relatív kockázatot. A példához lásd a ??. és a ??. fejezeteket is. A \(p\)-érték jelentése itt az, hogy a mintából kapott 2.56 szignifikánsan eltér 1-től (azért épp az 1-től, mert az, hogy a relatív kockázat 1, azt jelentené, hogy a kockázat mindkét csoportban ugyanakkora).
1.3 Hétköznapi valószínűségszámítás és statisztika
Ebben a részben arról szeretnénk meggyőzni az olvasót, hogy a statisztikai gondolkodáshoz szükséges szemléletmód csírájában mindnyájunkban megvan, hétköznapjainkban több-kevesebb tudatossággal használjuk is, de azért legtöbbünknek nem árt egy kis ,,rátanulás’‘, a fogalmak pontosítása, egyes fontos részletek tisztázása. Néha úgy érezzük, hogy nagy pechünk volt, vagy éppen nagy szerencse ért. ,,Azt vártam, hogy könnyű lesz a vizsga, mert az előző napi vizsgázók mind négyest-ötöst kaptak, tanultam is rá, mégis megbuktam. Pechem volt.’’ Amikor pechről vagy szerencséről beszélünk, mindig arról van szó – akár tudatosan, akár nem –, hogy egy bekövetkezett eseményt az előzetesen neki tulajdonított valószínűséggel vagy egy megfigyelt számértéket egy – különböző megfontolások alapján számított – feltételezett számértékkel szembesítünk.
Az új kolléga méltatlankodik a buszmegállóban: ,,Micsoda pechem van már megint! Öt napja dolgozom itt, és eddig mind az öt alkalommal a te buszod jött előbb!’‘. A régi kolléga nyugtatgatja: ,,Ugyan, nézd meg a menetrendet, mindkét busz tízpercenként jár, csak az enyém mindig egy perccel előbb érkezik, mint a tiéd. Így az esetek 90%-ában ugyan az enyém jön előbb, hosszú távon mégis ugyanannyi időt fogunk várakozással tölteni.’’
Ahhoz, hogy valamire azt mondhassuk, pech, a dolognak kellemetlennek, rossznak kell lennie. De egy rossz dolog még nem feltétlenül pech, csak ha emberi számítás szerint nem kellett volna bekövetkeznie. Hasonlóképpen, szerencséről akkor beszélünk, ha egy olyan jó dolog ér, amire előre nem számíthattunk. Amikor azt latolgatjuk, hogy egy elért nyeremény szerencsésnek nevezhető-e, akkor értékét egy olyan feltételezett értékkel – a nyeremény várható értékével – hasonlítjuk össze, amelyben benne foglaltatik a lehetséges nyereményeknek mind a nagysága, mind pedig a valószínűsége.
,,Óriási szerencsém volt, nagyon olcsón jutottam ehhez a lakáshoz’’ – meséli valaki. Amikor véleményt formálunk erről a kijelentésről, gondolatban kialakítunk magunkban egy reális vételárat a lakás helye, nagysága, állapota alapján (modell!), és a tényleges vételárat ezzel hasonlítjuk össze. Ha vannak ismereteink ugyanazon a környéken lévő, hasonló nagyságú és állapotú lakások eladási áráról, akkor hasonlíthatjuk ezekhez, vagy ezek átlagához (vagy mediánjához? modellválasztás!) az ismerősünk által fizetett árat (az átlagról és mediánról bővebben a ?? fejezetben). Az 1.6. ábrán tíz, hasonló paraméterekkel rendelkező lakás eladási ára látható az utóbbi hónapokból, fekete négyzet jelöli ismerősöm lakásának az árát. Ennek alapján mit gondolunk, valóban óriási szerencséje volt?
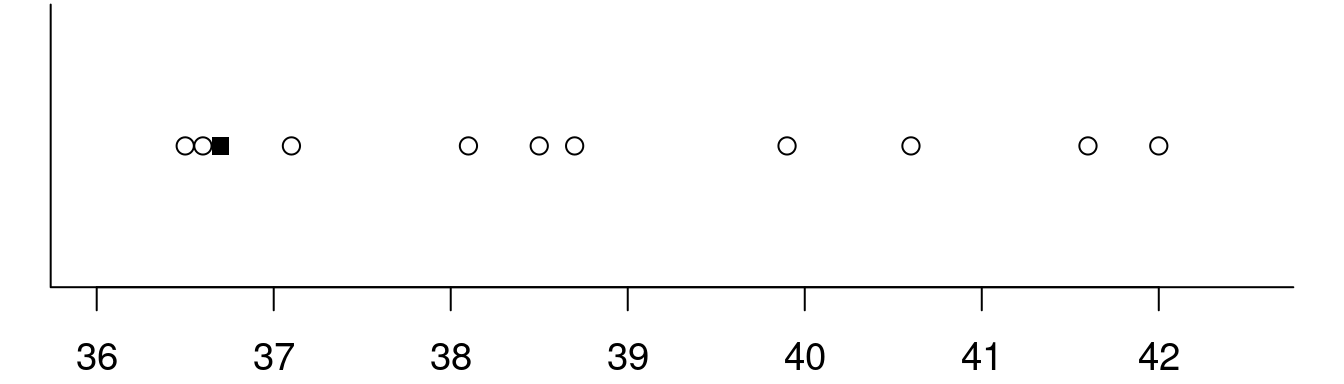
1.6: ábra. Tíz, az utóbbi hónapokban elkelt, barátoméhoz nagyjából hasonló lakás ára (millió forint). Minden kör egy-egy lakás árát jelöli, a négyzet a barátomét. Ennek alapján vajon jó vásárt csinált-e?
Persze a válasz attól függ, milyen ,,modellel’’ dolgozunk. Érvelhetünk úgy, hogy az átlagos árnál csaknem két és fél millióval olcsóbban jutott hozzá, tehát szerencséje volt. De gondolkozhatunk úgy is, hogy mivel az ábra szerint ilyen árfekvésben is vannak lakások, nem különösebb szerencse, hogy rátalált egyre. Igaz, mondhatjuk, mégiscsak szerencse, hiszen tíz közül nyolcan többet fizettek nála. Finomíthatjuk a modellt, ha belekalkuláljuk a lakáskereséssel töltött időt is, így esetleg szerencsének gondoljuk, ha egy hét alatt sikerült rátalálnia, de nem gondoljuk szerencsének, ha csak másfél év keresgélés után.
Néha úgy érezzük, hogy ismerősünk – mint az előbb a buszmegállóban – rosszul ítélte meg a körülményeket (rossz modellel dolgozott!), ekkor ilyen válaszokat adunk: ,,Miért mondod, hogy ez nagy pech? Hiszen ez mindenkivel számtalanszor megtörténik!’’ ,,Ne mondd, hogy peched volt! Én a helyedben éppen erre számítottam volna!’’ ,,Na ne szerénykedj! Miért lenne szerencse? Hiszen annyit dolgoztál érte, nagyon is megérdemled!’’
Új lakásba költöztem, most kezdem kitapasztalni, mikor kell elindulnom otthonról, hogy idejében beérjek a munkahelyemre. Ha tömegközlekedéssel megyek, az két átszállást jelent, tehát körülbelül egy óra utazásra számítok. Első nap minden jármű hamar jött, 53 perc alatt beértem. Második nap sokat is kellett várni, lassan is ment minden jármű, 72 percig tartott az utazás. Vajon első nap volt ritka szerencsém, vagy másnap volt pechem? Lehet ez is, az is, még nem tudom, majd meglátjuk, mi a jellemző. Úgy két hónap múlva már elég jól ismerem az utazással töltött idő eloszlását, nagyjából tudom, hogy hány perces utazás mennyire valószínű (1.6. ábra). Ötven megfigyelésből a leggyorsabb, illetve a leglassúbb utazás 45, ill. 72 perces volt. (Azok számára, akik már tanultak statisztikát, azt is eláruljuk, hogy az átlag 57.4, a medián pedig 57 perc.)
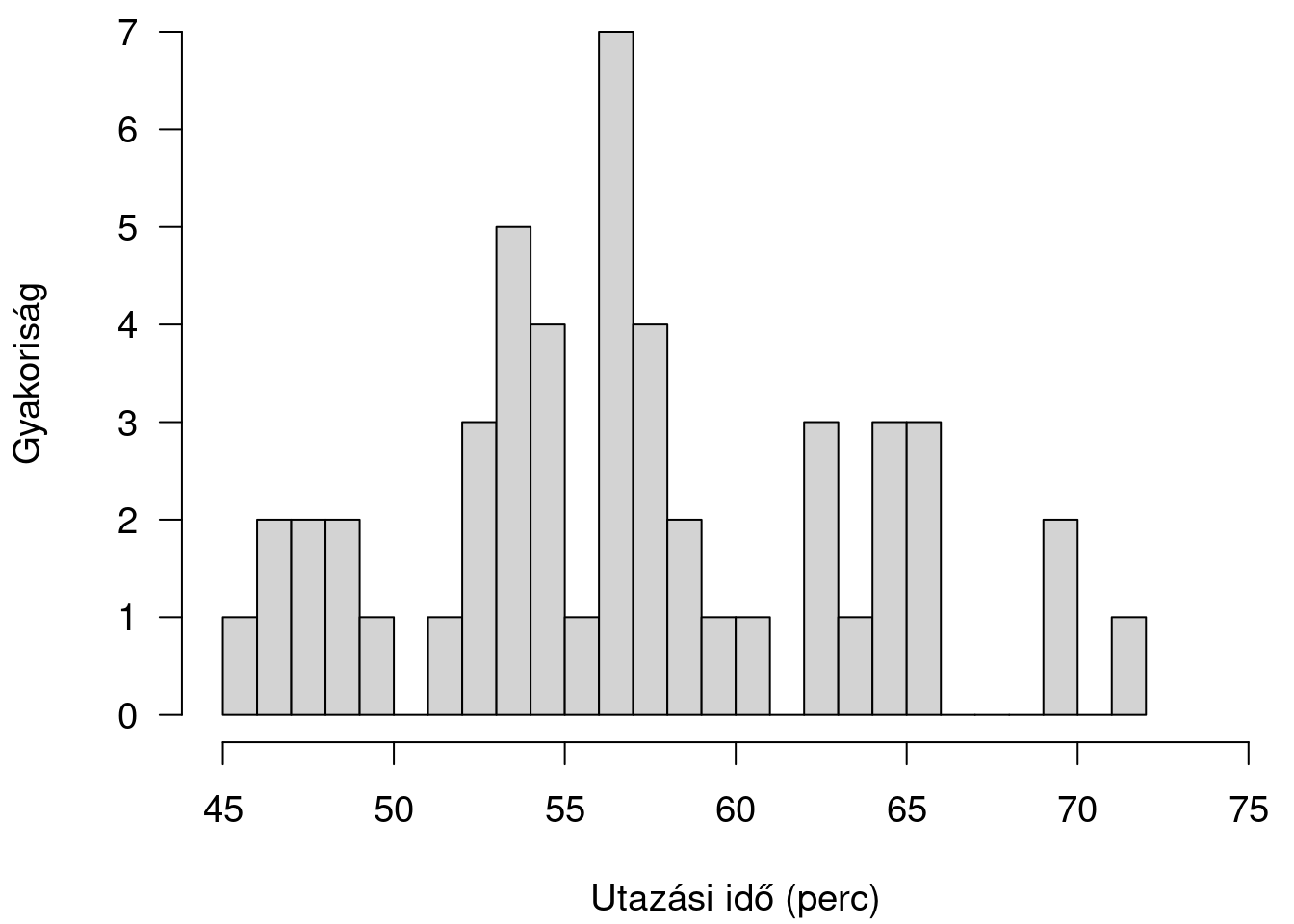
1.7: ábra. Az utazási idő megoszlása: a diagram az első ötven utazás adatait ábrázolja
Ennek alapján már látszik, hogy az első napi 53 perc nem különösebb szerencse, hiszen durván az esetek egyharmadában ennyi idő elegendő volt az utazásra. A második napi 72 perc viszont valóban ritka pechnek számít, ötvenből csupán egyszer tartott ilyen sokáig az út. Az ábrán látható mintázat – a több elkülönülő kis ,,dombocska’’ – inhomogenitást jelez, azt sugallja, hogy a vizsgált jelenség több különböző típus keveréke. A jelen példában gondolhatunk arra, hogy esetleg más utazási időre lehet számítani hétfőn, kedden és pénteken, vagy hogy a vizsgált 50 nap éppen augusztus-szeptemberre esik, és az ábrán a nyár és ősz közötti különbség jelenik meg. A ,,kilógó’’, a többiektől elkülönülő három értéket pedig valószínűleg valamilyen rendkívüli esemény (baleset, útlezárás) magyarázza. Az 50 megfigyelés alapján azt mondhatjuk, hogy az esetek 5–10%-ában számíthatunk ilyenre.
A tudományos kutatásban ezeknél gondosabban megtervezett megfigyelések vagy kísérletek alapján vonunk le bizonyos következtetéseket, de az esélyek mérlegelésére szolgáló gondolatmenetek a fentiekhez hasonlóak.